【Flume教程二】Flume采集到落地高可用HA配置(Flume to Kafka to HDFS)
目录
- 1 Flume-HA机器环境
- 2 Flume-HA架构图
- 3 Flume-HA架构特点
- 4 Flume-HA详细配置
- 4.1 Flume-Agent-A机器(api A 日志 ,flume采集到flume collector ha A-B)
- 4.2 Flume-Agent-B机器(api B 日志 ,flume采集到flume collector ha A-B)
- 4.3 Flume-Collector-A机器 (Flume Collector HA A ,flume采集到kafka)
- 4.4 Flume-Collector-B机器(Flume Collector HA B ,flume采集到kafka)
- 4.5 Flume-Agent-M机器(Kafka 消费者 M,flume采集到flume collector ha M-N)
- 4.6 Flume-Agent-N机器(Kafka 消费者 N ,flume采集到flume collector ha M-N)
- 4.7 Flume-Collector-M机器(Flume Collector HA M,flume写入到HDFS)
- 4.8 Flume-Collector-N机器(Flume Collector HA N,flume写入到HDFS)
- 5 Flume to HDFS NameNode HA 解决方案
- 6 Flume自定义JDK路径
- 7 Flume启动命令
- 8 Flume-HA总结
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。这里介绍一下《Flume高可用采集日志到kafka集群然后写入到HDFS的解决方案》。转载务必注明:https://cpp.la/472.html

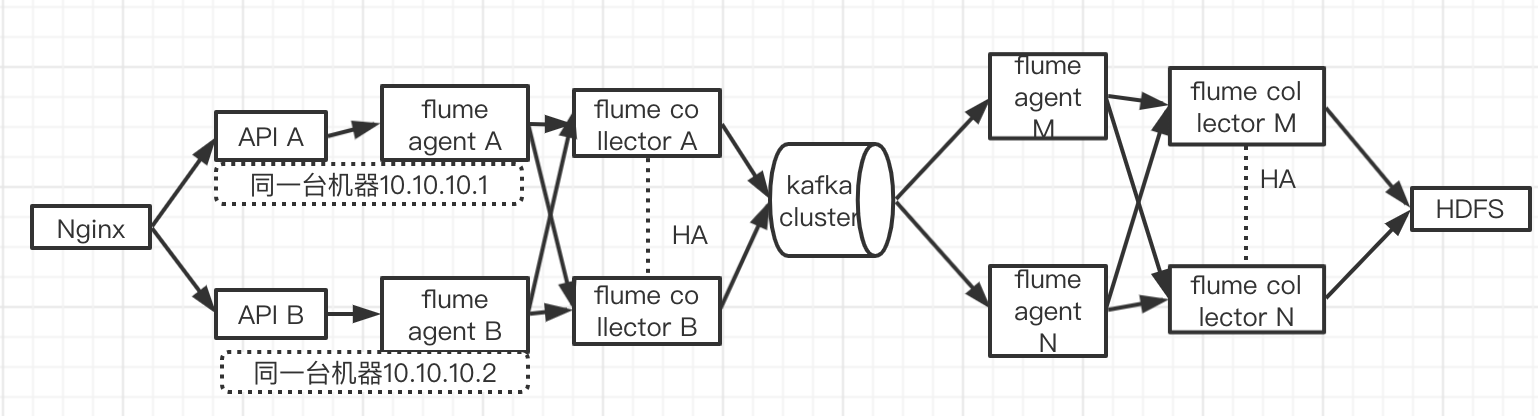
Flume-HA机器环境
为了节省资源,单组Flume agent 和 Flume Collector 放在了同一台机器。
- Nginx SLB集群一个
- 后端API服务 && Flume agent 机器
- Flume Collector && To Kafka 机器
- Kafka集群一个
- Flume agent From Kafka 机器
- Flume Collector && to HDFS机器
详细机器功能划分和机器IP如下
- API-Service-A:10.10.10.1(后端服务A,从Nginx分发过来的日志)
- API-Service-B:10.10.10.2(后端服务B,从Nginx分发过来的日志)
- Flume-Agent-A:10.10.10.1(采集AgentA,采集后端服务A的落地日志)
- Flume-Agent-B:10.10.10.2(采集AgentB,采集后端服务B的落地日志)
- Flume-Collector-A:10.10.10.1(Flume Collector Server and to Kafka A 机)
- Flume-Collector-B:10.10.10.2(Flume Collector Server and to Kafka B机)
- Flume-Agent-M:10.10.10.3(Kafka消费者M机)
- Flume-Agent-N:10.10.10.4(Kafka消费者N机)
- Flume-Collector-M:10.10.10.3(Flume Collector Server and to HDFS M机)
- Flume-Collector-N:10.10.10.4(Flume Collector Server and to HDFS N机)
Flume-HA架构图
Flume-HA架构特点
该架构具有高可用,高冗余,高性能,可任意扩展任何节点提高吞吐量的特点:
1、允许API WEB SEVICE任意一台主机宕机。(10.10.10.1 和 10.10.10.2)
2、允许flume collector A机和B机任意一台主机宕机。
3、kafka cluster 本身为高可用集群,不存在宕机问题。
4、允许flume agent M机和flume agent N机消费者任意一台主机宕机。
5、允许flume collector M机和flume collector N机任意一台主机 宕机。
6、API WEB SERVICE、Flume Collector A_B_HA集群、KAFKA、FLUME Agent M_N_Agent、Flume Collector M_N_HA集群各个节点均支持横向扩展。
Flume-HA详细配置
Flume-Agent-A机器(api A 日志 ,flume采集到flume collector ha A-B)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# tail to flume collector ha a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 a1.sinkgroups = g1 # Describe/configure the source a1.sources.r1.type = TAILDIR # 偏移量 a1.sources.r1.positionFile = /opt/apiserver/log/positionoffset.log # 文件组,支持定义多个 a1.sources.r1.filegroups = f1 f2 # 第一组监控的是test1文件夹中的什么文件:.log文件 # # a1.sources.r1.filegroups.f1 = /opt/module/flume/data/test1/.*log # 第二组监控的是test2文件夹中的什么文件:以.txt结尾的文件 # # a1.sources.r1.filegroups.f2 = /opt/module/flume/data/test2/.*txt a1.sources.r1.filegroups.f1 = /opt/apiserver/log/dd.log a1.sources.r1.filegroups.f2 = /opt/apiserver/log/dd.txt # set sink1 a1.sinks.k1.type = avro a1.sinks.k1.hostname = 10.10.10.1 a1.sinks.k1.port = 52020 # set sink2 a1.sinks.k2.type = avro a1.sinks.k2.hostname = 10.10.10.2 a1.sinks.k2.port = 52020 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1500000 a1.channels.c1.transactionCapacity = 10000 #set sink group a1.sinkgroups.g1.sinks = k1 k2 #set failover a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 10 a1.sinkgroups.g1.processor.priority.k2 = 1 a1.sinkgroups.g1.processor.maxpenalty = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k2.channel = c1 a1.sinks.k1.channel = c1 |
Flume-Agent-B机器(api B 日志 ,flume采集到flume collector ha A-B)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# tail to flume collector ha a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 a1.sinkgroups = g1 # Describe/configure the source a1.sources.r1.type = TAILDIR # 偏移量 a1.sources.r1.positionFile = /opt/apiserver/log/positionoffset.log # 文件组,支持定义多个 a1.sources.r1.filegroups = f1 f2 # 第一组监控的是test1文件夹中的什么文件:.log文件 # # a1.sources.r1.filegroups.f1 = /opt/module/flume/data/test1/.*log # 第二组监控的是test2文件夹中的什么文件:以.txt结尾的文件 # # a1.sources.r1.filegroups.f2 = /opt/module/flume/data/test2/.*txt a1.sources.r1.filegroups.f1 = /opt/apiserver/log/dd.log a1.sources.r1.filegroups.f2 = /opt/apiserver/log/dd.txt # set sink1 a1.sinks.k1.type = avro a1.sinks.k1.hostname = 10.10.10.1 a1.sinks.k1.port = 52020 # set sink2 a1.sinks.k2.type = avro a1.sinks.k2.hostname = 10.10.10.2 a1.sinks.k2.port = 52020 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1500000 a1.channels.c1.transactionCapacity = 10000 #set sink group a1.sinkgroups.g1.sinks = k1 k2 #set failover a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 10 a1.sinkgroups.g1.processor.priority.k2 = 1 a1.sinkgroups.g1.processor.maxpenalty = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k2.channel = c1 a1.sinks.k1.channel = c1 |
Flume-Collector-A机器 (Flume Collector HA A ,flume采集到kafka)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# flume to kafka, avro collector a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type = avro a1.sources.r1.bind = 10.10.10.1 a1.sources.r1.port = 52020 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Collector a1.sources.r1.interceptors.i1.value = 10.10.10.1 # channel-1000000-10000 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.keep-alive = 60 # this kafka buffer api is for collection for anywhere a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = bi_dd a1.sinks.k1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092 a1.sinks.k1.kafka.flumeBatchSize = 2000 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 100 a1.sinks.k1.kafka.producer.compression.type = snappy # bind a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
Flume-Collector-B机器(Flume Collector HA B ,flume采集到kafka)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# flume to kafka, avro collector a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type = avro a1.sources.r1.bind = 10.10.10.2 a1.sources.r1.port = 52020 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Collector a1.sources.r1.interceptors.i1.value = 10.10.10.2 # channel-1000000-10000 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.keep-alive = 60 # this kafka buffer api is for collection for anywhere a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = bi_dd a1.sinks.k1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092 a1.sinks.k1.kafka.flumeBatchSize = 2000 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 100 a1.sinks.k1.kafka.producer.compression.type = snappy # bind a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
Flume-Agent-M机器(Kafka 消费者 M,flume采集到flume collector ha M-N)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# kafka consumer a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 a1.sinkgroups = g1 # Describe/configure the source a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092 a1.sources.r1.kafka.consumer.group.id = flume_api_dd a1.sources.r1.kafka.topics = api_dd # set sink1 a1.sinks.k1.type = avro a1.sinks.k1.hostname = 10.10.10.3 a1.sinks.k1.port = 52020 # set sink2 a1.sinks.k2.type = avro a1.sinks.k2.hostname = 10.10.10.4 a1.sinks.k2.port = 52020 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1500000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.keep-alive = 60 #set sink group a1.sinkgroups.g1.sinks = k1 k2 #set failover a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 10 a1.sinkgroups.g1.processor.priority.k2 = 1 a1.sinkgroups.g1.processor.maxpenalty = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k2.channel = c1 a1.sinks.k1.channel = c1 |
Flume-Agent-N机器(Kafka 消费者 N ,flume采集到flume collector ha M-N)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# kafka consumer a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 a1.sinkgroups = g1 # Describe/configure the source a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092 a1.sources.r1.kafka.consumer.group.id = flume_api_dd a1.sources.r1.kafka.topics = api_dd # set sink1 a1.sinks.k1.type = avro a1.sinks.k1.hostname = 10.10.10.3 a1.sinks.k1.port = 52020 # set sink2 a1.sinks.k2.type = avro a1.sinks.k2.hostname = 10.10.10.4 a1.sinks.k2.port = 52020 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1500000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.keep-alive = 60 #set sink group a1.sinkgroups.g1.sinks = k1 k2 #set failover a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 10 a1.sinkgroups.g1.processor.priority.k2 = 1 a1.sinkgroups.g1.processor.maxpenalty = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k2.channel = c1 a1.sinks.k1.channel = c1 |
Flume-Collector-M机器(Flume Collector HA M,flume写入到HDFS)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# flume to hdfs a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = avro a1.sources.r1.bind = 10.10.10.3 a1.sources.r1.port = 52020 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Collector a1.sources.r1.interceptors.i1.value = 10.10.10.3 # Describe the sink a1.sinks.k1.type = hdfs #a1.sinks.k1.hdfs.path = hdfs://hdfshost:9000/test/api_dd/%Y%m%d a1.sinks.k1.hdfs.path = /flume/api_dd/%Y-%m-%d a1.sinks.k1.hdfs.useLocalTimeStamp = false a1.sinks.k1.hdfs.writeFormat = Text #上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs-10.10.10.3- #上传文件的后缀 a1.sinks.k1.hdfs.fileSuffix = .data #设置文件类型,可支持压缩 a1.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件, 2小时 a1.sinks.k1.hdfs.rollInterval = 7200 a1.sinks.k1.hdfs.rollSize = 12800000000 #文件的滚动与Event数量无关 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.threadsPoolSize = 10 #重新定义时间单位 a1.sinks.k1.hdfs.roundUnit = hour #是否按照时间滚动文件夹 a1.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a1.sinks.k1.hdfs.roundValue = 1 #是否使用本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a1.sinks.k1.hdfs.batchSize = 2000 a1.sinks.k1.hdfs.threadsPoolSize = 10 # 调用hdfs命令时超时时间,这里调大一倍,单位毫秒 a1.sinks.k1.hdfs.callTimeout=900000 # 关闭HDFS文件出错时重试次数,之前设为0即无限重试。现在改为60 a1.sinks.k1.hdfs.closeTries=60 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1500000 a1.channels.c1.transactionCapacity = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
Flume-Collector-N机器(Flume Collector HA N,flume写入到HDFS)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# flume to hdfs a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = avro a1.sources.r1.bind = 10.10.10.4 a1.sources.r1.port = 52020 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Collector a1.sources.r1.interceptors.i1.value = 10.10.10.4 # Describe the sink a1.sinks.k1.type = hdfs #a1.sinks.k1.hdfs.path = hdfs://hdfshost:9000/test/api_dd/%Y%m%d a1.sinks.k1.hdfs.path = /flume/api_dd/%Y-%m-%d a1.sinks.k1.hdfs.useLocalTimeStamp = false a1.sinks.k1.hdfs.writeFormat = Text #上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs-10.10.10.4- #上传文件的后缀 a1.sinks.k1.hdfs.fileSuffix = .data #设置文件类型,可支持压缩 a1.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件, 2小时 a1.sinks.k1.hdfs.rollInterval = 7200 a1.sinks.k1.hdfs.rollSize = 12800000000 #文件的滚动与Event数量无关 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.threadsPoolSize = 10 #重新定义时间单位 a1.sinks.k1.hdfs.roundUnit = hour #是否按照时间滚动文件夹 a1.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a1.sinks.k1.hdfs.roundValue = 1 #是否使用本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a1.sinks.k1.hdfs.batchSize = 2000 a1.sinks.k1.hdfs.threadsPoolSize = 10 # 调用hdfs命令时超时时间,这里调大一倍,单位毫秒 a1.sinks.k1.hdfs.callTimeout=900000 # 关闭HDFS文件出错时重试次数,之前设为0即无限重试。现在改为60 a1.sinks.k1.hdfs.closeTries=60 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1500000 a1.channels.c1.transactionCapacity = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
Flume to HDFS NameNode HA 解决方案
直接把core-site.xml和hdfs-site.xml拷贝到flume的conf目录下 然后flume to hdfs配置文件中如下配置就可以了:
a1.sinks.k1.hdfs.path = /flume/api_dd/%Y-%m-%d
Flume自定义JDK路径
一、进入flume/conf文件夹下,cp flume-env.sh.template to flume-env.sh
二、vim flume-env.sh ,尾部追加jdk路径即可 export JAVA_HOME=/opt/jdk1.8
Flume启动命令
|
1 2 3 4 5 6 7 8 9 10 11 |
# flume to hdfs, flume collector server(M and N分别启动) nohup bin/flume-ng agent -c conf -f conf/flume2hdfs -n a1 -Dflume.root.logger=ERROR,console >> /opt/log/flume2hdfs.log & # kafka to flume, flume agent(M and N分别启动) nohup bin/flume-ng agent -c conf -f conf/kafka2flume -n a1 -Dflume.root.logger=ERROR,console >> /opt/log/kafka2flume.log & # flume to kafka, flume collector server(A and B分别启动) nohup bin/flume-ng agent -c conf -f conf/flume2kafka -n a1 -Dflume.root.logger=ERROR,console >> /opt/log/flume2kafka.log & # tail to flume, flume agent (A and B分别启动) nohup bin/flume-ng agent -c conf -f conf/tail2flume -n a1 -Dflume.root.logger=ERROR,console >> /opt/log/tail2flume.log & |
Flume-HA总结
Flume Source 和 Sinks 犹如管道,支持并联、串联等各种冗余。利用其特性可以轻松组合出支持高可用,大吞吐量的大数据流。