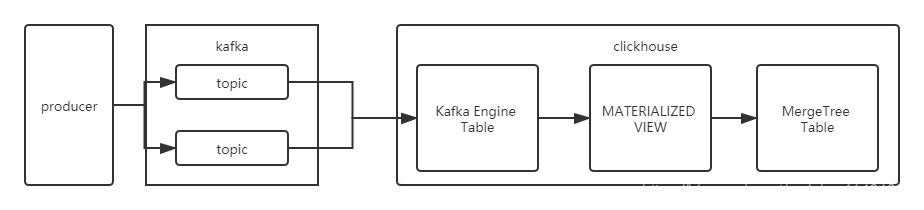
ClickHouse-Kafka引擎,kafka to clickhouse详细教程
目录
《ClickHouse-Kafka引擎,kafka to clickhouse详细教程》,ClickHouse要甩掉Hadoop单飞了,ClickHouse 这几年频繁更新,甩掉了各种中间件、采集工具单飞。 仅且不限于MySQL物化引擎直接采集到ClickHouse,Kafka引擎直接采集到ClickHouse 等等。 感觉ClickHouse要成神。分享一下kafka引擎在ClickHouse中的应用。
![]()
|
1 |
create database cppla on cluster company_cluster; |
一、创建存储消费数据表
- 创建kafka_readings用于接收Kafka的数据
- MergeTree 指定创建表的引擎
- PARTITION BY 指定我们的分区数据
- ORDER BY 指定我们的排序即索引
- dt字段为具体业务时间。
|
1 2 3 4 5 6 7 |
CREATE TABLE cppla.kafka_readings ( dd_by_cppla String, msg String, platform String, data String, dt DateTime ) Engine = MergeTree PARTITION BY toYYYYMMDD(dt) ORDER BY (dt); |
二、创建消费Kafka数据表
- kafka_broker_list kafka消费集群的broker列表
- kafka_topic_list 消费kafka的Topic
- kafka_group_name kafka消费组
- kafka_format 消费数据的格式化类型,JSONEachRow表示每行一条数据的json格式,如果需要输入嵌套的json,设置input_format_import_nested_json=1。更多:https://clickhouse.tech/docs/en/interfaces/formats/
- kafka_skip_broken_messages 表示忽略解析异常的Kafka数据的条数。如果出现了N条异常后,后台线程结束,Materialized View会被重新安排后台线程去监听数据
- kafka_num_consumers 单个Kafka Engine 的消费者数量,通过增加该参数,可以提高消费数据吞吐,但总数不应超过对应topic的partitions总数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE cppla.kafka_readings_queue ( dd_by_cppla String, msg String, platform String, data String, dt DateTime ) ENGINE = Kafka SETTINGS kafka_broker_list = '172.21.0.5:49153,172.21.0.5:49154,172.21.0.5:49155', kafka_topic_list = 'test_2', kafka_group_name = 'consumer_group2', kafka_format = 'JSONEachRow', kafka_skip_broken_messages = 20000, kafka_num_consumers = 1; |
三、创建物化视图合并表传输数据,导入到ClickHouse
|
1 2 3 |
CREATE MATERIALIZED VIEW cppla.kafka_readings_view TO cppla.kafka_readings AS SELECT dd_by_cppla, msg, platform, data, dt FROM cppla.kafka_readings_queue; |
四、往kafka写入消息,数据被即时存储
|
1 2 3 4 |
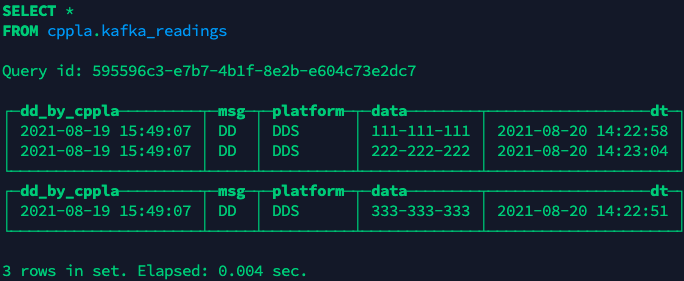
# docker exec -ti kafka-docker_kafka_1 /opt/kafka/bin/kafka-console-producer.sh --broker-list 172.21.0.5:49154 --topic test_2 {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"111-111-111","dt":"2021-08-20 14:22:58"} {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"222-222-222","dt":"2021-08-20 14:23:04"} {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"333-333-333","dt":"2021-08-20 14:22:51"} |
五、维护:停止接收kafka消息,卸载物化视图
注意:最好先停止kafka消息的写入,避免大批量消息写入过多堆积,来不及消费。
|
1 |
DETACH TABLE cppla.kafka_readings_view ; |
六、维护:恢复接收kafka消息,继续作业
|
1 |
ATTACH TABLE cppla.kafka_readings_view; |
七、创建复制表 + 分布式表 + 视图数据落地
7.1 创建复制表保证数据安全
注意一:这里ReplicatedReplacingMergeTree做合并时,重复数据会被去重删除。所以这里务必注意创建合理的order by。
原话: flush data from a Kafka engine table into a Distributed table. It requires more careful configuration, though. In particular, the Distributed table needs to have some sharding key (not a random hash). This is required in order for the deduplication of ReplicatedMergeTree to work properly. Distributed tables will retry inserts of the same block, and those can be deduped by ClickHouse.
注意二:Clickhouse-kafka引擎极端情况无法保证不重复,所以最好利用ReplicatedReplacingMergeTree表引擎依据业务分区去重处理。
- 使用ORDER BY 排序键作为判断数据是否重复的唯一键
- 只有在合并分区时才会触发删除重复数据的逻辑
- 只能在相同分区的数据去重,跨分区不会去重。即使使用OPTIMIZE TABL也不会垮分区去重
- 数据去重策略,如果没有设置ver版本号,则保留同一组重复数据的最后一行;如果设置了ver版本号,则保留同一组重复数据中ver字段取值最大的那一行。
原话:but ClickHouse as a kafka client can currently guarantee only at-least-once. And in some corner cases (connection lost etc) you can get duplicates.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE cppla.kafka_readings_replicated ON CLUSTER company_cluster ( _offset UInt64, _partition UInt64, _timestamp Nullable(DateTime), dd_by_cppla String, msg String, platform String, data String, dt DateTime ) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/replicated/{shard}/kafka_readings_replicated_cppla', '{replica}') PARTITION BY toYYYYMMDD(dt) ORDER BY (_offset, _partition) TTL dt + toIntervalDay(365) SETTINGS index_granularity = 8192, use_minimalistic_part_header_in_zookeeper = 1; |
7.2 创建视图落地到ClickHouse
|
1 2 3 |
CREATE MATERIALIZED VIEW cppla.kafka_readings_replicated_view TO cppla.kafka_readings_replicated AS SELECT _offset, _partition, _timestamp, dd_by_cppla, msg, platform, data, dt FROM cppla.kafka_readings_queue; |
7.3 创建分布式表加速查询
|
1 2 |
CREATE TABLE cppla.kafka_readings_distributed ON CLUSTER company_cluster AS cppla.kafka_readings_replicated ENGINE = Distributed('company_cluster', cppla, kafka_readings_replicated, rand()); |
八、往Kafka写入新消息,查询数据
|
1 2 3 |
{"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"aaa-aaa-aaa","dt":"2021-08-23 12:32:17"} {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"bbb-bbb-bbb","dt":"2021-08-23 12:32:23"} {"dd_by_cppla":"2021-08-19 15:49:07","msg":"DD","platform":"DDS","data":"ccc-ccc-ccc","dt":"2021-08-23 12:32:29"} |
8.1 查看MergeTree引擎的存储表
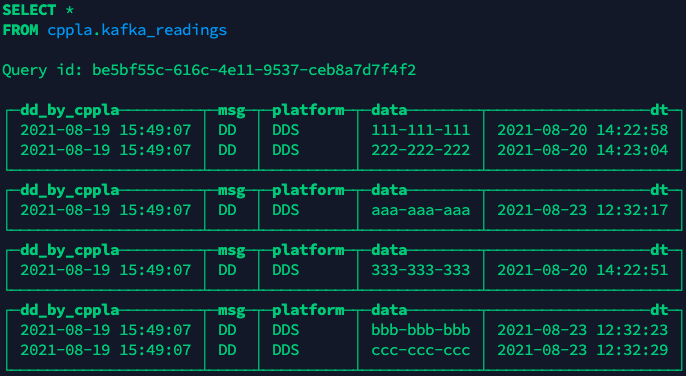
8.2 查看分布式引擎的新存储表
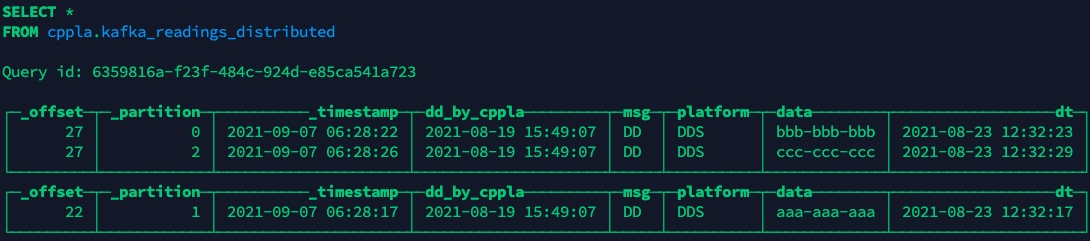
即多视图可以消费同一个Kafka数据表并加以落地存储:cppla.kafka_readings_queue
《ClickHouse-Kafka引擎,kafka to clickhouse详细教程》,文章有参阅ClickHouse官网和Google上的一些文献。by:cpp.la
2 Replies to “ClickHouse-Kafka引擎,kafka to clickhouse详细教程”