Linux中Python程序CPU占用高排查
Linux中Python程序CPU占用高排查,Linux中Python程序CPU占用高排查,Linux中Python程序CPU占用高排查
kafka-python==2.0.2和 gevent 新版本 生产机器中发现CPU占用极高,应该是有bug:https://github.com/dpkp/kafka-python/issues/2168 。目前推测是gevent patch后Kafka Consumer 和 heartbeat 占用了大量的 CPU 。

机器环境
- Debian 10
- Python 3.7.3
- kafka-python 2.0.2
- gevent 21.12.0 (greenlet 1.1.2)
测试代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 |
# vim cppla.py from gevent import monkey from gevent.pywsgi import WSGIServer monkey.patch_all() from multiprocessing import cpu_count, Process from flask import Flask, jsonify from kafka import KafkaConsumer, KafkaProducer from kafka.errors import NoBrokersAvailable, KafkaTimeoutError app = Flask(__name__) @app.route("/cppla", methods=['GET']) def function_benchmark(): return jsonify( { "status": "ok", } ), 200 def run(): mulserver = WSGIServer(('0.0.0.0', 8080), app) mulserver.start() def server_forever(): mulserver.start_accepting() mulserver._stop_event.wait() for i in range(cpu_count()): p = Process(target=server_forever) p.start() KAFKA_URI = { "BOOTSTRAP_SERVERS": [ '192.168.1.2:9092', '192.168.1.3:9092', '192.168.1.4:9092' ], "TOPIC": "test", "GROUP_ID": "v1", "KEY": "order" } class kafkaClient(object): def __init__(self): print("init start ") self._producer_client = self._createProducer self._consumer_client = self._createConsumer print("init end ") @property def _createProducer(self): try: return KafkaProducer( bootstrap_servers=KAFKA_URI["BOOTSTRAP_SERVERS"], retries=3 ) except NoBrokersAvailable: print("bo brokers") @property def _createConsumer(self): try: return KafkaConsumer( KAFKA_URI["TOPIC"], group_id=KAFKA_URI["GROUP_ID"], bootstrap_servers=KAFKA_URI["BOOTSTRAP_SERVERS"], auto_offset_reset="latest", enable_auto_commit=True, auto_commit_interval_ms=5000, ) except NoBrokersAvailable: print("no brokers") @property def consumer(self): print("consumer function") try: for x in self._consumer_client: yield { "partition": x.partition, "timestamp": x.timestamp, "offset": x.offset, "value": x.value.decode() } except Exception as e: print(e) def producer(self, msg): print("consumer function") if not self._producer_client: print("mark0") return False else: try: pre = datetime.datetime.now() self._producer_client.send( topic=KAFKA_URI["TOPIC"], key=KAFKA_URI["KEY"].encode(), value=msg.encode() ).add_callback(self.on_send_success).add_errback(self.on_send_error) next = datetime.datetime.now() if (next-pre).seconds > 60: print("60s") return True except KafkaTimeoutError as e: print("timeout") except Exception as e: print("exception") return False def on_send_success(self, metadata): print(metadata) def on_send_error(self, excp): print("excp") kafka_client = kafkaClient() if __name__ == "__main__": run() |
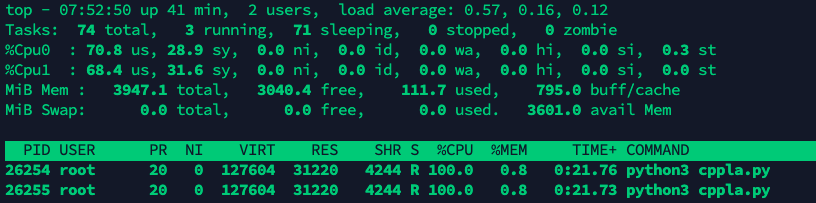
top查看cpu占用
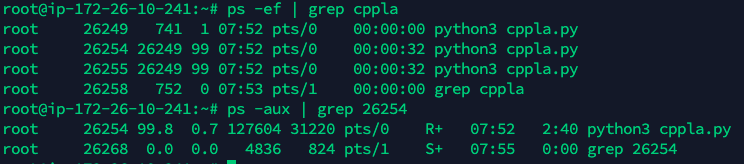
ps查看程序
|
1 2 3 |
ps -ef | grep cppla ps -aux | grep 26254 |
进程的线程CPU占用情况
|
1 2 |
top -H -p 26254 # 这个程序未开启线程 |
跟踪进程的执行堆栈
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
注意debian apt下的pstack无法使用,乱码,谷歌上找到了Centos下的pstack脚本 # vim pstack.sh #!/bin/sh if test $# -ne 1; then echo "Usage: `basename $0 .sh` <process-id>" 1>&2 exit 1 fi if test ! -r /proc/$1; then echo "Process $1 not found." 1>&2 exit 1 fi # GDB doesn't allow "thread apply all bt" when the process isn't # threaded; need to peek at the process to determine if that or the # simpler "bt" should be used. backtrace="bt" if test -d /proc/$1/task ; then # Newer kernel; has a task/ directory. if test `/bin/ls /proc/$1/task | /usr/bin/wc -l` -gt 1 2>/dev/null ; then backtrace="thread apply all bt" fi elif test -f /proc/$1/maps ; then # Older kernel; go by it loading libpthread. if /bin/grep -e libpthread /proc/$1/maps > /dev/null 2>&1 ; then backtrace="thread apply all bt" fi fi GDB=${GDB:-/usr/bin/gdb} # Run GDB, strip out unwanted noise. # --readnever is no longer used since .gdb_index is now in use. $GDB --quiet -nx $GDBARGS /proc/$1/exe $1 <<EOF 2>&1 | set width 0 set height 0 set pagination no $backtrace EOF /bin/sed -n \ -e 's/^\((gdb) \)*//' \ -e '/^#/p' \ -e '/^Thread/p' watch ./pstack.sh 26254 |
跟踪结果如下,gevent长时间再做epoll_wait,epoll_poll操作?
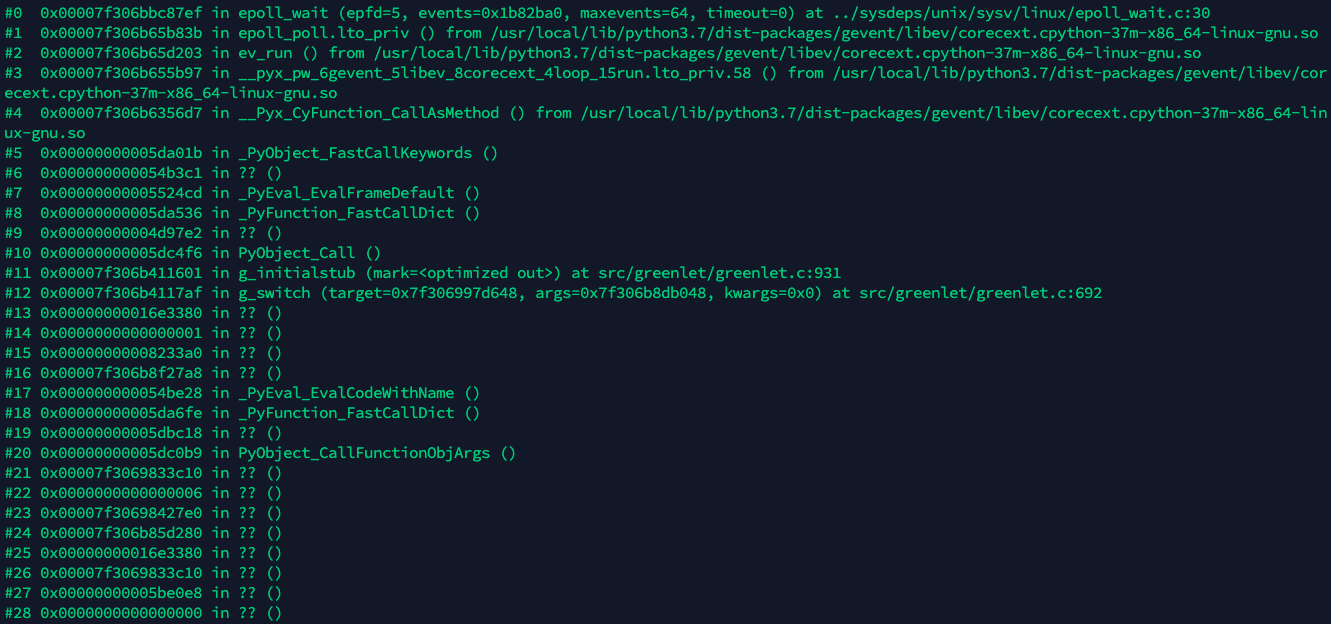
跟踪函数的调用
|
1 2 |
# apt install strace strace -f -p 26254 |
执行结果
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# epoll_wait dead loop getpid() = 26254 clock_gettime(CLOCK_MONOTONIC, {tv_sec=4174, tv_nsec=439918115}) = 0 clock_gettime(CLOCK_MONOTONIC, {tv_sec=4174, tv_nsec=439940304}) = 0 epoll_wait(5, [{EPOLLOUT, {u32=7, u64=12884901895}}], 64, 0) = 1 clock_gettime(CLOCK_MONOTONIC, {tv_sec=4174, tv_nsec=439983956}) = 0 getpid() = 26254 clock_gettime(CLOCK_MONOTONIC, {tv_sec=4174, tv_nsec=440030506}) = 0 clock_gettime(CLOCK_MONOTONIC, {tv_sec=4174, tv_nsec=440052716}) = 0 epoll_wait(5, [{EPOLLOUT, {u32=7, u64=12884901895}}], 64, 0) = 1 clock_gettime(CLOCK_MONOTONIC, {tv_sec=4174, tv_nsec=440096569}) = 0 |
调试结果
I test my code again , high cpu, environment:gevent == 20.9.0 and kafka-python == 1.4.7
I test my code again , normal cpu, environment:gevent == 1.5.0 and kafka-python == 2.0.2
But in github issues another test gevent==20.9.0 and kafka-python == 1.4.7 is normal.
monkey后,gevent在做大量的epoll wait操作。 直接导致了死循环。处理方案:gevent降级为gevent==1.5.0 (greenlet==0.4.15)后,一切正常。