Ray分布式计算探究
介绍
伯克利开源的一个高性能分布式AI计算框架,兼容TensorFlow、PyTorch与MXNet。旨在取代spark,因为业界认为Spark对于一些现实的人工智能应用而言速度太慢了。
测试环境
- 硬件: linode 3台单核CPU E5-2680V3,1G内存
- 系统: debian9
- 环境: python 2.7.13 & ray 0.4
测试目标
执行10次一亿内的叠加运算
代码示例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
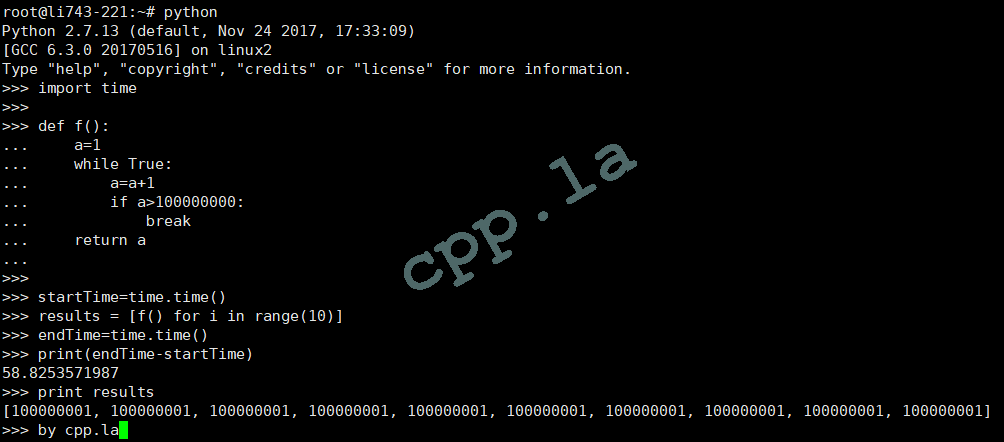
# 单机测试代码 import time def f(): a=1 while True: a=a+1 if a>100000000: break return a startTime=time.time() results = [f() for i in range(10)] endTime=time.time() print(endTime-startTime) print results |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
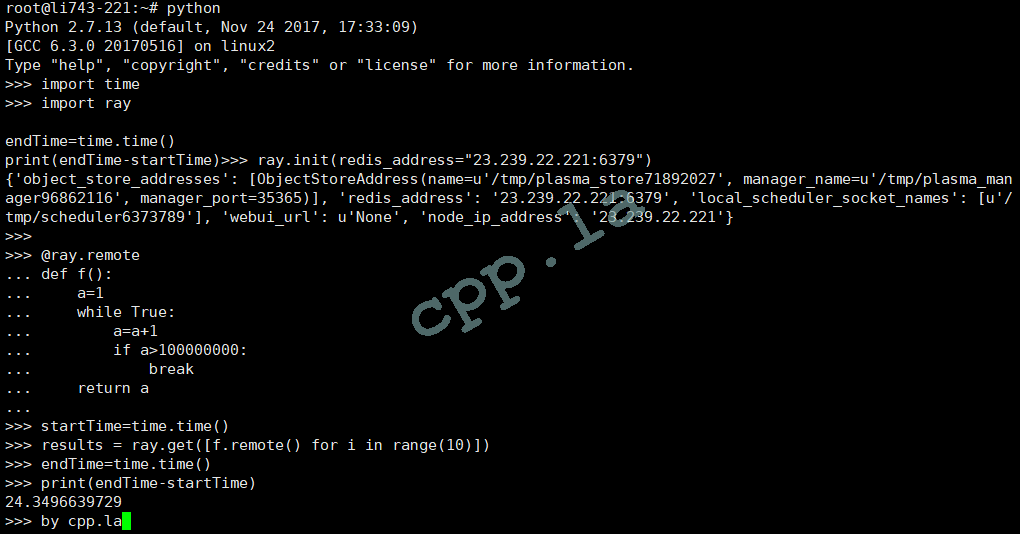
# 集群测试代码 import time import ray ray.init(redis_address="23.239.22.221:6379") @ray.remote def f(): a=1 while True: a=a+1 if a>100000000: break return a startTime=time.time() results = ray.get([f.remote() for i in range(10)]) endTime=time.time() print(endTime-startTime) |
python单机测试
计算时的CPU占用如下:
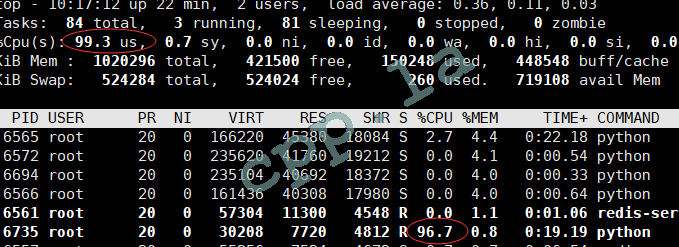
计算总耗时:
ray集群测试
三台计算节点集群展示:
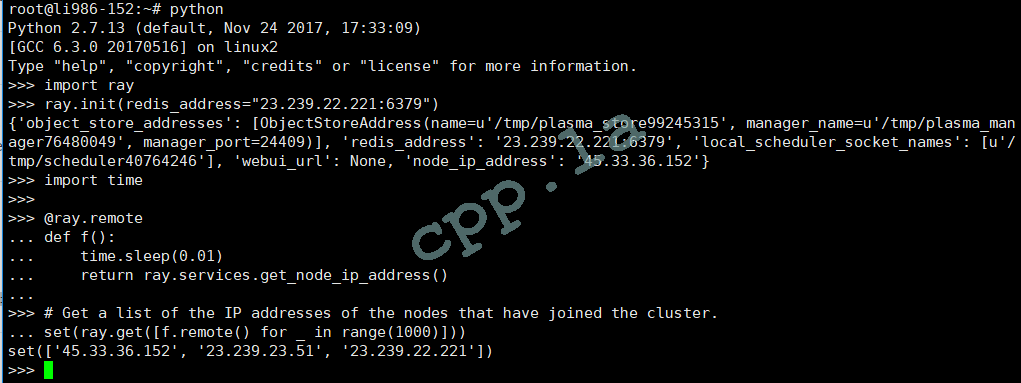
三台计算总耗时:
三台计算执行时CPU均为%100,在此不在贴图。
后记
测试图表上看,单机变分布式,单车瞬间变摩托!
这里并没有提及ray的原理以及架构,请参考:https://github.com/ray-project/ray。 另外准备尝试在大数据实时流测试环境中集成,替换掉spark,估计有不少坑要踩。