RabbitMQ、RocketMQ、Kafka消息中间件的对比
目录
消息中间件的主要作用
解耦、削峰、流控 ,比如说秒杀活动,网站访问流控,大规模吞吐等等。
1、业务日常解耦对于超大规模集群,大规模吞吐,QPS,TPS提升非常重要,“盗图”来简单示例
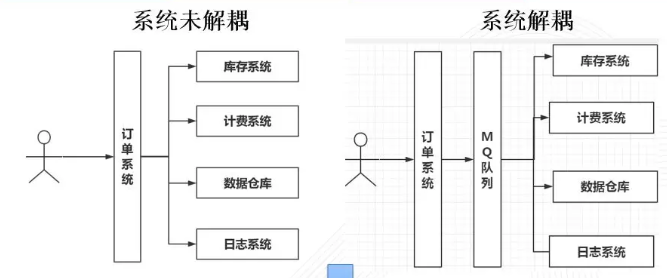
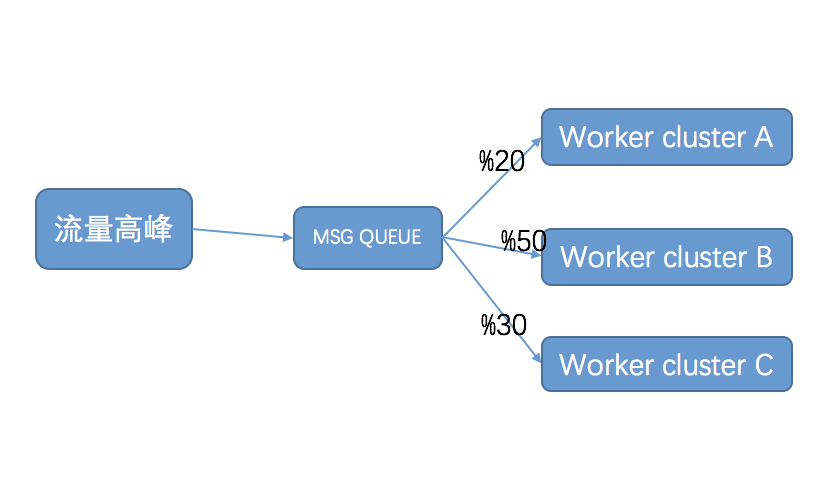
2、削峰和流控
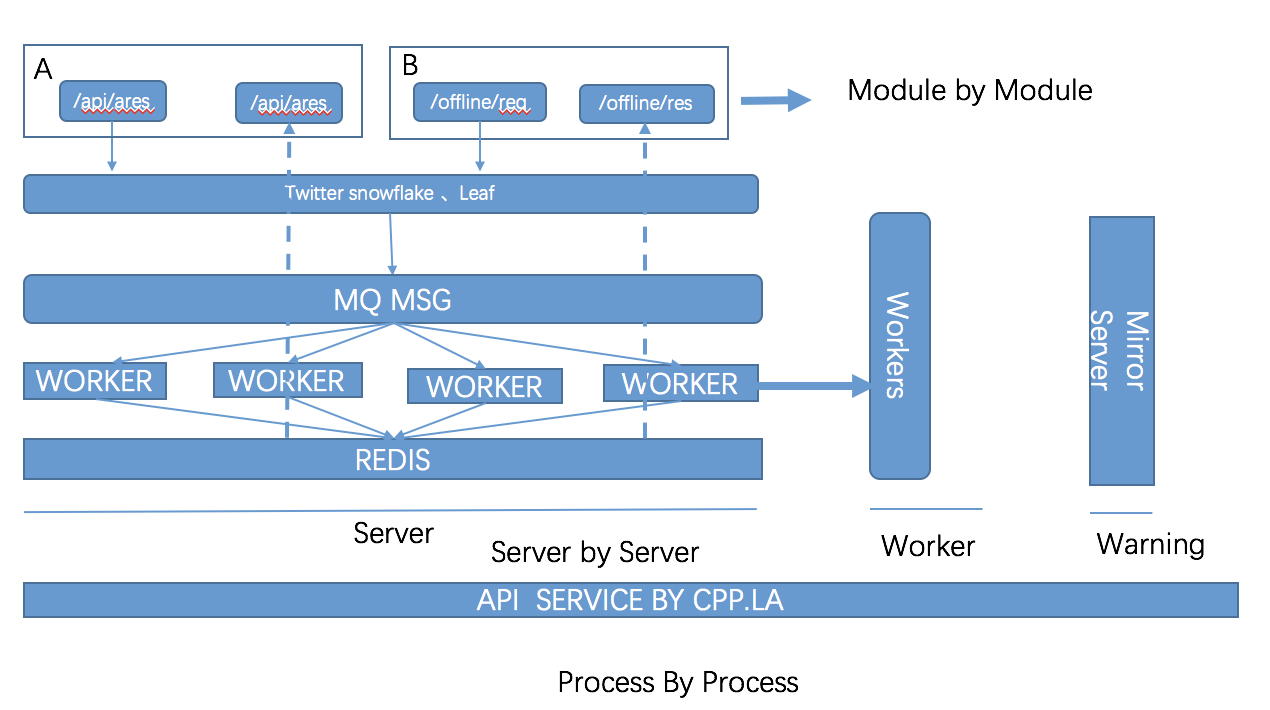
消息中间件在服务中的应用架构
工作中的RESTFUL API服务中消息中间件的实际应用场景。架构图如下:
RabbitMQ
rabbitMQ 几万级数据量,基于erlang语言开发,因此响应速度快些,并且社区活跃度比较活跃,可视化界面。缺点就是数据吞吐量相对与小一些,并且是基于erlang语言开发,比较重的问题难以维护。
高可用
rabbitMQ为主从模式,即镜像模式概念,就是用户在发送数据时候,发送到mq机器上,并且持久化磁盘,然后通过设置镜像的queue,把数的持久化地址对应表同步到另外mq机器上。这种就有效防止一台mq挂了以后,另外的mq可以直接对外提供消费功能
消息丢失
rabbitMQ从生产者,消费者,消息队列角度分析。生产者而言,发送消息如果失败,则定义重试次数,一般设置成五次。两种解决方式1.通过设置事务,进行事务回滚重试。2.通过发送者确认模式开启。
RocketMQ
rocketMQ几十万级别数据量,基于Java开发,应对了淘宝双十一考验,并且文档十分的完善,拥有一些其他消息队列不具备的高级特性,如定时推送,其他消息队列是延迟推送,如rabbitMq通过设置expire字段设置延迟推送时间。又比如rocketmq实现分布式事务,比较可靠的,十分适合金融领域的消息中间件。
高可用
rocketMQ为分布式架构,分为多主集群结构,多主多备异步复制结构,多主多备同步复制结构。
消息丢失
发送者确认模式开启,消息持久化默认开启,消费者消费开启手动ack
Kafka
kafka真正的大规模分布式消息队列,能偶支撑百万级的TPS,基于zookeeper实现的分布式消息订阅(Kafka最近正在酝酿大版本,将提供自管理的元数据仲裁机制)。 常用数据采集,传输,存储解耦等等。追求极高的吞吐量
高可用
kafka可用性非常高,因为它是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用
消息丢失
- 同步模式:确认机制设置为ack=-1,也就是让消息写入leader和所有的副本。
- 异步模式:确认机制设置为ack=0,不限制阻塞超时时间,也就是生产端一直阻塞着,这样也能保证消息不丢失。
在数据消费时,避免数据丢失的方法:如果使用了storm,要开启storm的ackfail机制;如果没有使用storm,确认数据被完成处理之后,再更新offset值。低级API中需要手动控制offset值。