ClickHouse从Hive中导入超大规模数据(适用于MySQL)
ClickHouse从Hive中导入超大数据(适用于MySQL),如何从hive中快速导出数据到ClickHouse?如何快速地将Hive中的数据导入ClickHouse?Hive t0 ClickHouse, How to Import data from Hive to Clickhouse quickly ?
![]()
一、背景
我们这里需要快速将Hive 数仓导入ClickHouse来完成实时OLAP即席查询。
- Hive 离线数据仓库每天凌晨左右跑完,数据量不少,
- Hive 文件存储格式为ORC File。
- 上层数仓一般对应为宽表,字段比较多,ClickHouse中为强类型。
- 为什么不用Flink, Spark?有时候恰恰相反我们需要的是一个实时OLAP。
二、解决方案
期间也查询过大量资料,最终采用的方案为2.1 《HiveToClickHouse架构方案图一》,这样做能比方案2.2《HiveToClickHouse架构方案图二》减少1次IO。我们这里实际生产过程中DWS和DWD同步起来数据大几百G,“hive -e” 可能是最好的方式。且直接用多线程主动导入到ClickHouse分片机中, 能够节省IO,更快的利用ClickHouse分布式引擎进行查询。
2.1 HiveToClickHouse架构方案图一架构实现的具体步骤
- 将hive数据仓库导出到机器本地硬盘。
- 启动和生产机同CPU核数的进程。
- 单一进程10w条记录/次,随机散列(random.shuffle)到三台ClickHouse分片机本地表。

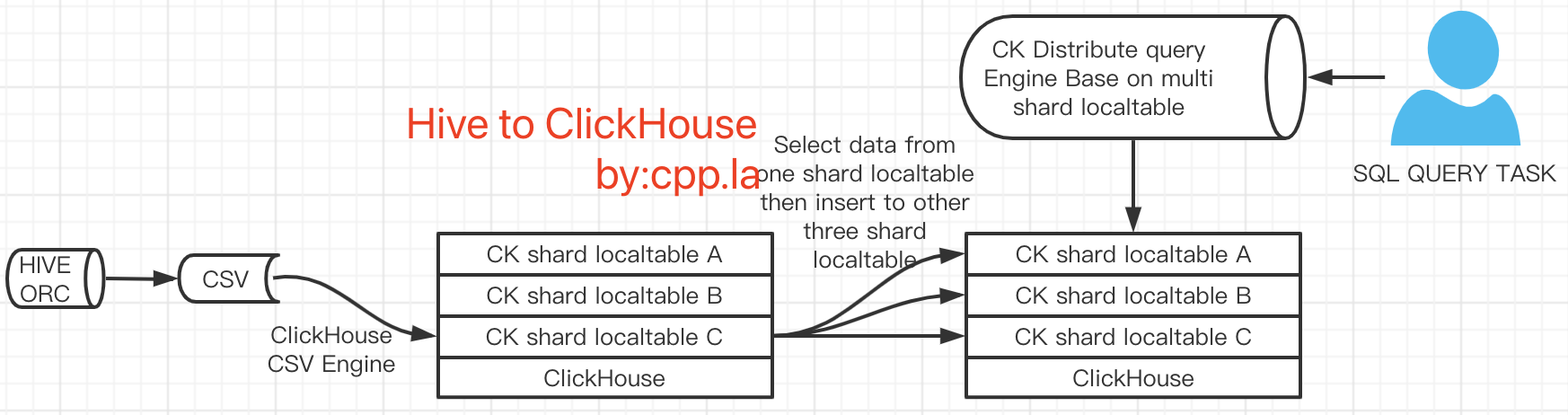
2.2 HiveToClickHouse架构方案图二架构实现的具体步骤
- 将hive数据仓库导出到机器本地硬盘。
- 利用ClickHouse提供的CSV引擎将CSV数据文件映射到ClickHouse单一分片机的本地表中。
- 将数据从ClickHouse单一分片机的本地表中取出来,然后随机散列到三台ClickHouse分片机本地表。(可利用select data insert data实现;另外也可以利用clickhouse-copier来实现。然而呢实际测试中效果均不太理想)
- clickhouse-copier:https://clickhouse.tech/docs/zh/operations/utilities/clickhouse-copier/
ClickHouse从Hive中导入超大规模数据(适用于MySQL),2021-04-19, by:cpp.la